This is the third blog, in the four-part series to develop an understanding of how to maintain the ordering of messages while architecting a solution. I would highly recommend you to go through both of the previous blogs on Kafka Message Ordering where I have detailed out the:
- Factors that can disrupt message ordering at producer level – Kafka Message Ordering Part – 1
- Factors responsible for altering message ordering at the infrastructure layer and consumer side – Kafka Message Ordering Part – 2
The objective of this blog is to present a solution that can be adapted to meet real-time ordered message ingestion using big data technology stack. We all know about the small file problem with namenodes in a Hadoop cluster, which essentially means that a Hadoop cluster should be used with a relatively small number of large files instead of a large number of small files. When we talk about real-time direct ingress of the messages coming over Kafka (assuming message sizes are up to a couple of MBs only) then it is essentially a small file problem. Unless we have a backend persistence layer to handle record/message level CRUD(create, read, update and delete) operations, we will not be able to operate in real-time. There are two such data stores that are used quite often and provide the above-mentioned CRUD functionality in the purview of bigdata: Apache HBase and Apache Kudu. There are other data stores as well like Cassandra, MongoDB, etc but here we won’t consider them due to either consistency problems or data storage format requirements.
As we know from the previous blogs, there could be broadly two types of message ordering issues:
- Individual events are coming out of order at the event collection hub (late-arriving data)
- Individual events are grouped together and then divided into manageable chunks of messages. These messages can arrive from producer to consumer in out of order
The solution for both of these scenarios follows the same architecture and can use either HBase or Apache Kudu.
Apache HBase: Despite some drawbacks, HBase is a great tool to employ in real-time use cases. In our scenario, we want to handle the messages coming out of sequence on the consumer side and ensure that we always see the correct state of data. Assuming the architecture below:

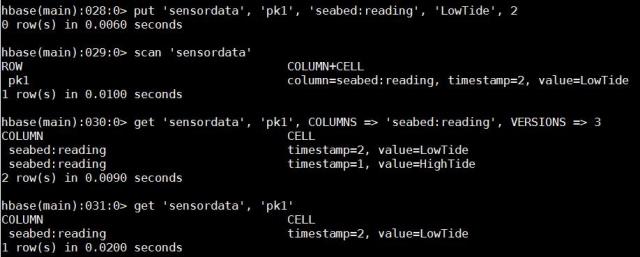
With HBase as a data store here, it is quite easy to manage CRUD operations at the record (message) level and even column (message attribute) level. For illustrative purposes, I am using an HBase shell but in real-time implementations, API usage is recommended. For the sensor setup in the first blog, suppose we create a table sensordata with one column family seabed as:

If you describe it:

Let’s now store data in a column in seabed column family at a timestamp 1,

where sensordata is the table name, the seabed is column family name, pk1 is row key, reading is a column in seabed column family, HighTide is the value of the reading column for the given row key, and 1 is the timestamp (just kept it simple enough for our example). If we query this row:

Similarly adding a couple more rows and querying them:
Now consider that we need to process the data from a Kafka Topic in perfect order and we have used HBase as an intermediate transient store. Assume that we have late-arriving data wherein the message with the latest timestamp(t=10) lands and processed earlier than previously generated messages (with timestamps = 7,8,9).

As we can see above HBase alleviates a lot of concerns around message/event order due to its inbuilt feature around time-based data versioning, even at the column level. So irrespective of any changes in the message ordering at any previous layer we can manage data integrity at all points in time. With HBase versioning, we can not only pull the latest message but all historical versions for the same key when required.
For any incoming message we need to store the message attributes (columns in a table/column family) and when we retrieve the data we would always get the one that is the latest among the processed messages for a given key. This behavior can be extended to any message processing framework which can log data/message in HBase. Ensure that for real-time use cases the data footprint in HBase needs to be kept lite and hence it is better to have a recurrent batch process to offload data from HBase to HDFS storage.
We will continue our discussion in the next blog, Kafka Message Ordering Part 4, where we would cover the alternate solution for Kafka message ordering issues.